Timings und Latenzen
Bereits auf der diesjährigen CeBIT konnte man bei verschiedenen Speicherherstellern vernehmen, dass Nvidias nForce 4 SLI Intel Edition in Sachen Timings und somit auch im Bereich der Bandbreite für Aufsehen sorgen wird. Für die deutlich schärferen Timings soll ein extra (Pre-)Prozessor bzw. eine ganze Reihe solcher Einrichtungen sorgen, welcher bzw. welche Nvidia in den Memory-Controller integriert hat. Der so genannte Dynamic Adaptive Speculative Preprocessor (DASP) 3.0 soll gemeinsam mit der QuickSync Technology diese Aufgaben übernehmen und die erste nForce Generation für Intel-Plattformen auch leistungsmäßig zum ersten Platz in der Highscore verhelfen. DASP dürfte vielen Lesern unbekannt sein, findet aber bereits seit der ersten nForce Generation für Athlon XP und Duron Prozessoren Verwendung in den Core-Logic Lösungen von Nvidia – Version 1.0 im nForce- und 2.0 im nForce 2-Chipsatz.
Dynamic Adaptive Speculative Preprocessor 3.0
Bevor wir auf den Sinn und Nutzen des DASP eingehen, möchten wir noch einmal kurz die Problematik der Speichertimings und der damit verbundenen Latenzen umreisen: Der Memory-Controller sieht die verschiedenen DRAM-Bänke als so genannte Pages an und kann aus diesen Informationen lesen. Die benötigten Informationen werden aus den hinterlegten Zeilen (Rows) geholt und in die für den Transfer nötigen Sense Amplifiers (kurz: Sense Amps) geschoben, wo sie nun dem Memory-Controller bzw. der CPU bereit stehen. Befindet sich die gewünschte Information in einer DRAM-Bank welche zudem auch den Status „Page open“ signalisiert, spricht man von einem „Page Hit“ – die Daten können mit minimaler Verzögerung/Latenz bezogen und zur CPU weitergeleitet werden. Sollte sich das gewünschte Bit in einer Bank mit geschlossener Page (closed Page) befinden, spricht man von einem „Page Miss with closed Page“ – die nötige Page muss nun geöffnet werden um die Daten zu transferieren, was zusätzliche Zeit in Anspruch nimmt und die Geschwindigkeit des Vorgangs senkt. Die meiste Zeit benötigt ein Zugriff auf eine Bank die momentan eine falsche, nicht benötigte Page geöffnet hat, da zuerst die alte Page geschlossen und die neue geöffnet werden muss. In diesem Fall spricht man von einem „Page miss with open Page“. Technologien wie Hyper-Threading setzen den ganzen Vorgängen in Sachen Komplexität natürlich die absolute Krone auf und verlangen den Ingeneuren aktueller Controller-Lösungen alles ab! Multi-Core ist hier natürlich auch ein wichtiges Thema und lässt die Zahl der parallelen Threads und die damit verbundene Datenflut an die RAMs weiter steigen.
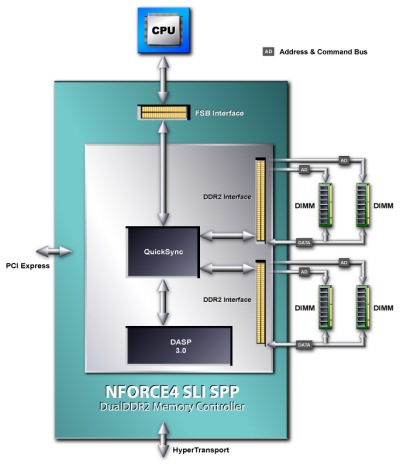
An dieser Stelle tritt nun Nvidias Dynamic Adaptive Speculative Preprocessor in Aktion. Diese Konstruktion soll etwaige Speicherzugriffe durch passende Vorhersagen beschleunigen – der Preprocessor trifft Aussagen über die Wahrscheinlichkeit, welche Pages als nächstes benötigt werden. Hiermit will man den oben erwähnten „Page miss with closed Page“ oder gar den Zustand „Page miss with open Page“ verhindern und die Latenzen drücken. DASP 3.0 ist dabei in der Lage anstehende Instruktionen und ganze Threads zu erkennen, zu analysieren und nach vorgegebenen Algorithmen die nötigen Schritte für (wahrscheinlich) kommende Kommandos einzuleiten – zum Beispiel Schließen/Öffnen von Pages. Das System arbeitet sogar so intelligent, dass es einen passenden Algorithmus aus dem Repertoire auswählt oder einen völlig neuen Ablauf, aus Kompositionen verschiedener Algorithmen, erstellt, um die Latenzen zu minimieren. Laut Nvidia soll sich DASP in Version 3.0 so bemerkbar wie noch nie machen!
QuickSync Technology
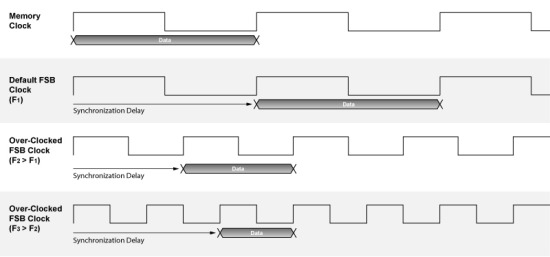
Wie der Name bereits erahnen lässt, hat QuickSync in der Praxis etwas mit Synchronisation zu tun – richtig! Nvidia QuickSync sorgt für die Takt-Synchronisation der Daten zwischen Prozessor/Northbridge (Front Side Bus) und Speicher/Northbridge (Memory Clock). Da die beiden Frequenzen (FSB und Memory) unabhängig von einander gesteuert und auch in der Praxis nicht immer mit gleicher Geschwindigkeit betrieben werden (können), ist hier eine Synchronisation nötig. Die neue QuickSync Technology von Nvidia soll diese Vorgänge zeitlich minimieren und zusätzliche Latenzen einsparen. Noch einmal zur Erinnerung: Bereits Nvidias nForce 2 Chipsatz zeigte das Phänomen, dass eine Konfiguration mit identischem Front Side Bus und Speichertakt mehr Performance ermöglicht, als beispielsweise ein System in dem der Speichertakt etwas über dem FSB liegt. Dies soll beim nForce 4 SLI Intel Edition Chipsatz dank QuickSync nicht der Fall sein! Ergo, maximale Taktraten ergeben maximale Performance...
Autor: Patrick von Brunn



