
Um den Sinn und Zweck der neuen Unified Shader-Architektur besser verstehen zu können, möchten wir vorab nochmals kurz auf den Aufbau der bisherigen, "klassischen" Pipeline eingehen. Die klassische Pipeline setzt sich dabei im Wesentlichen aus vier Teilen zusammen: Vertex, Setup (Grafik: Triangle), Pixel und ROP. Dabei betreten die vom Prozessor gelieferten Daten zuerst die Vertex-Stufe (Vertex-Shader), die primär für die Berechnung von Formveränderungen und Lichteinfalländerungen zuständig ist. Die zweite Stufe berechnet aus den Vertices (Plural von Vertex, dem Eckpunkt eines Polygons) entsprechend primitive Gebilde, wie beispielsweise Linien (Verbindung zwischen zwei Vertices) und Dreiecke (Verbindung zwischen drei Vertices). Diese Primitiven werden anschließend in Fragmente (Fragments) überführt und den durch den Programmierer vorgesehenen Abläufen unterworfen. Dabei ist der Pixel-Shader zum Beispiel für Interpolationen mit Texturen beim Shading zuständig, um möglichst realistische Darstellungen zu ermöglichen. Z-Testing (Sichtbarkeit von Objekten), Framebuffer-Blending (Vermischen mit Pixeln aus dem Framebuffer; Beispiel: Transparenz) oder Anti-Aliasing (Kantenglättung) wird anschließend durch die Stufe ROP (Raster Operations) realisiert. Die so durch die GPU bzw. die Pipelines geführten Daten, die ursprünglich von der CPU geliefert wurden, werden nun in den Grafikspeicher (Framebuffer) geschoben und stehen für die Ausgabe auf dem Monitor bereit.
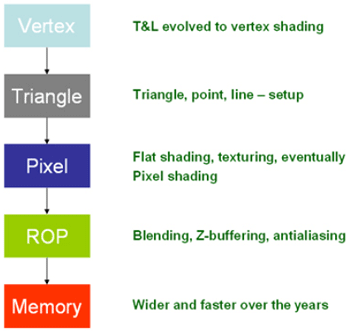
Die Struktur der klassischen 3D-Pipeline im Überblick.
Das klassische Design sieht also einen festen, sequentiellen Verlauf der Berechnungen vor und gibt zudem auch den Umfang bzw. die Rechenleistung der jeweiligen Stufen (Stages) an. Hier liegt einer der wesentlichen Knackpunkte im Unterschied der beiden Architekturen: Statt des stupiden Durchlaufs der Daten durch die klassischen Pipelines, setzt Nvidia bei Unified Shader auf das mehrfache Hintereinanderschalten so genannter "Stream Prozessoren" (Stream Processors, kurz: SP). Diese SPs taugen dabei für alle Arten der Berechnungen, die Vertex, Setup und Pixel umfassen. Wir schicken also unsere anfallenden Daten von der CPU in die neue G80-GPU und "Loopen" von den Vertex-Berechnungen bis hin zum Pixel-Shader von SP zu SP und übergeben die Daten anschließend der ROP-Stage, um diese abschließend in den Framebuffer zu schreiben. Kurz gesagt werden die Stufen Vertex, Setup und Pixel durch die neuen SPs ersetzt. Diese Floating-Point-Prozessoren sind dabei noch deutlich intelligenter und können zusätzlich auch physikalische Berechnungen (Physics; mehr dazu auf Seite 4) und Geometrie-Daten (Geometry; Teil von DirectX 10, siehe Seite 6) verarbeiten. Daraus ergibt sich schließlich die brandneue Unified-Pipeline, wie sie im folgenden Bild dargestellt ist.
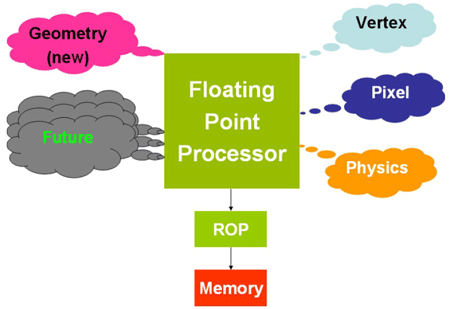
Die Unified-Pipeline soll dem G80 zum Erfolg verhelfen.
Das ganze lässt sich nun auch an einem hübschen Beispiel verdeutlichen, in dem wir eine GPU mit 8 Pixel-Shadern und 4 Vertex-Shadern annehmen. Die folgenden Szenen (Bild links) zeigen eine sehr stark von der Vertex-Leistung abhängige Berechnung und eine Pixel-Shader-lastige Darstellung. Entsprechend ergibt sich jeweils nicht benötigte Hardware, da im Falle von Vertex-Last die Pixel-Shader kaum beansprucht werden und umgekehrt genauso. Insgesamt 12 Shader können also nicht maximal effizient arbeiten, da sie lediglich für eine einzige Art der Berechnung konzipiert und entsprechend optimiert wurden.
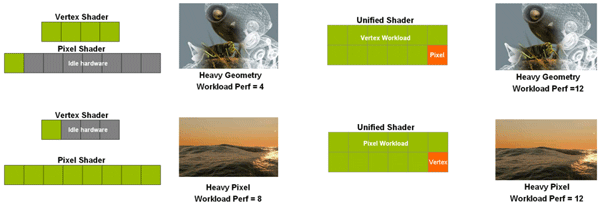
Links: Berechnung mithilfe der klassischen 3D-Pipeline.
Rechts: Unified Shader bzw. SPs in Aktion.
Vergleich wir den klassischen Fall mit einer Unified-Pipeline mit ebenfalls 12 Shadern (Bild rechts), können wir hier eine maximale Ausnutzung der zur Verfügung stehenden Resourcen vermelden: Die 12 Shader lassen sich je nach anfallenden Daten in ihrer Ausrichtung anpassen und es kommt nicht zum Leerlauf. Hierfür zuständig ist eine so genannte "Dispatch and Control"-Logik, die den SPs ihre jeweiligen "Aufträge" zuordnet. Dadurch will man nicht nur eine höhere Performance erreichen, sondern auch den Programmierern mehr Freiraum geben, da man künftig nicht mehr zwingend auf ein ausgewogenes Pixel-Vertex-Verhältnis achten muss. Übrigens: Nvidias Ingenieure entwickelten die Unified Shader-Architektur für den G80 seit dem Jahr 2002.
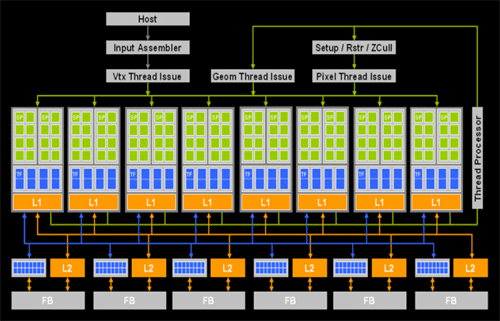
Die Unified Shader-Architektur im Falle der GeForce 8800 GTX im Detail.
Du willst ein Armband, das beim ersten Versuch richtig passt und bequem sitzt. Fang deshalb nicht bei Farbe oder Material...
Viele Menschen nutzen ihre Kopfhörer täglich – sei es bei der Arbeit, beim Gaming oder unterwegs. Doch nach längerer Nutzung...
Ein mobiles Klimagerät ist ein nützlicher Helfer in den heißen Sommermonaten. Es verschafft schnelle Abkühlung, kann die Luft entfeuchten und...
Toshiba Electronics Europe kündigt mit der M12-Serie neue 3,5-Zoll-Nearline-HDDs für Hyperscaler und Cloud Service Provider an, die große Rechenzentren betreiben....
Mit der PNY CS3250 M.2 NVMe PCIe Gen5 x4 SSD erweitert PNY sein Portfolio im High-End-Segment um ein Modell, das...

Mit der iCHILL Frostbite bietet INNO3D eine GeForce RTX 5090 Grafikkarte mit Wasserkühlblock von Alphacool an. Wir hatten die Gelegenheit diesen extravaganten Boliden im Testlab auf Herz und Nieren zu prüfen.

Mit der GeForce RTX 5070 Ti HOF Gaming bietet Grafikkarten-Spezialist KFA2 einen besonders extravaganten Boliden mit großem OC-Potenzial an. Wir durften im Praxistest einen Blick auf die Black Edition der Karte werfen.

Im günstigeren Preissegment hat Nvidia die GeForce RTX 5070 installiert, die auf der abgespeckten Blackwell-Variante GB205 basiert. Wir haben uns ein Custom-Design von Hersteller KFA2 im Test genauer angesehen.